
THUẬT TOÁN YOLOV3 CẢI THIỆN để phát hiện trạng thái an toàn của Pantograph
2022-08-02 09:13Trừu tượng: Pantograph là một thành phần quan trọng kết nối đầu máy toa xe với lưới cung cấp điện, vì vậy trạng thái an toàn của pantograph là rất quan trọng đối với hoạt động trơn tru và ổn định của toa xe.
Trong bài báo này, bằng cách phân tích từng khung hình, hình ảnh video của máy sao chép được theo dõi bởi hệ thống giám sát video trên tàu, trạng thái an toàn của máy sao chép được theo dõi trong thời gian thực bằng cách sửa đổi thuật toán nhận dạng mục tiêu YOLOV3 được sử dụng rộng rãi trong ngành để xác định cấu trúc. sự bất thường, tia lửa và sự xâm nhập của vật thể lạ vào máy sao chép cùng một lúc. Các thử nghiệm đã chứng minh rằng một kênh duy nhất có thể đạt tốc độ 40 khung hình/giây trên máy chủ phân tích thông minh tích hợp Tienuo. Độ chính xác phát hiện toàn diện mAP@0,5 có thể đạt 98%, đạt được kết quả phát hiện thời gian thực và tương đối chính xác.
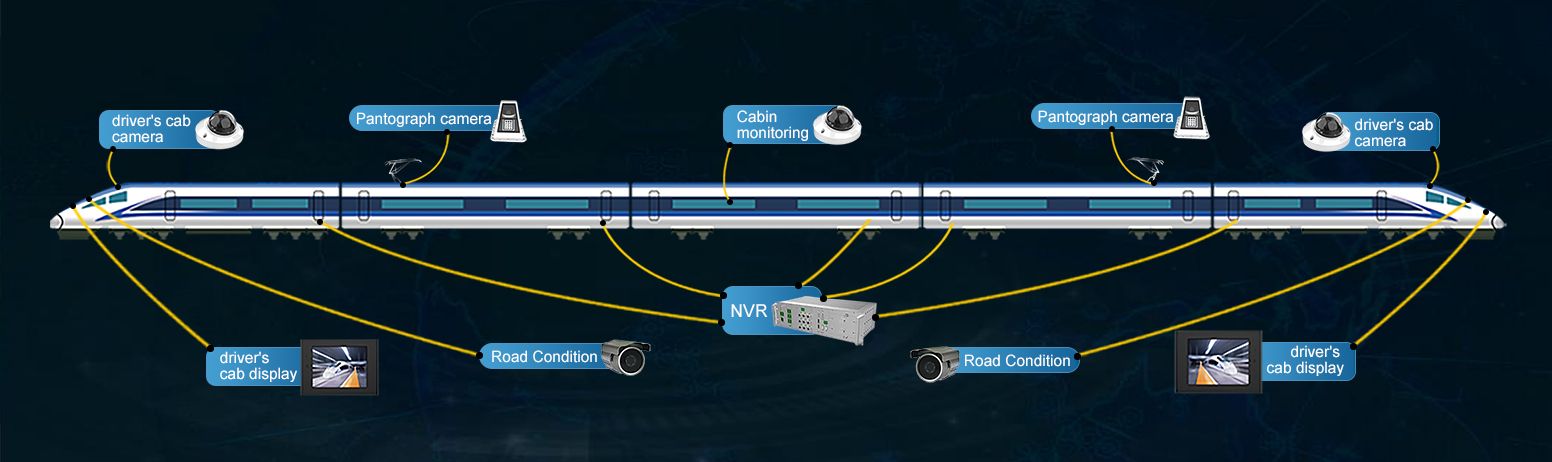
1. Giám sát thông minh các pantograph
Các thuật toán nhận dạng mục tiêu điển hình dựa trên học sâu ngày nay là các thuật toán hai giai đoạn như thuật toán Faster R-CNN và các thuật toán một giai đoạn như thuật toán YOLOV3. Thuật toán YOLO không cần tính toán khung ứng cử viên trước so với R- Mạng CNN, giúp giảm nỗ lực tính toán và có thể đạt được tốc độ tính toán nhanh hơn. Và thuật toán YOLOV3 cải thiện sự thiếu sót trong phát hiện đa quy mô của thế hệ thuật toán YOLO trước đó bằng cách có ba nhánh trong phần mạng nhận dạng, có thể giải quyết vấn đề nhận dạng mục tiêu ở ba quy mô: nhỏ, trung bình và lớn. Ngoài ra, thuật toán YOLOV3 có hỗ trợ kỹ thuật tốt hơn và được sử dụng trong danh dự công nghiệp trong một số lượng lớn ứng dụng. Vì vậy, trong bài báo này,
2. Xây dựng thuật toán phát hiện trạng thái an toàn của Pantograph
2.1 Trừu tượng mục tiêu
Phát hiện trạng thái an toàn của pantograph có thể được chia thành phát hiện bất thường cấu trúc pantograph, phát hiện cháy pantograph, phát hiện vật thể lạ xâm nhập, v.v. Trong số đó, bất thường cấu trúc pantograph có thể được chia thành biến dạng tấm trượt carbon, nghiêng, gãy góc trái và phải, trái và thiếu góc cung bên phải, v.v. Các trạng thái tiêu chuẩn, bất thường được thể hiện trong Hình 1B-F.

Hình 1 Các tiêu chuẩn ghi nhãn thuật toán và trạng thái an toàn của Pantograph
Để sử dụng thuật toán nhận dạng mục tiêu, trước tiên cần phải trừu tượng hóa mục tiêu nhận dạng để phát hiện trạng thái an toàn của máy sao chép và mục tiêu nhận dạng trừu tượng được thể hiện trong Hình 1. Các máy sao chép trong điều kiện bình thường và trạng thái bất thường được dán nhãn thống nhất. Các mục tiêu như đĩa cung và góc cung ở trạng thái bình thường và đĩa cung và góc cung ở trạng thái bất thường và các tia lửa và vật lạ được đánh dấu. Sau đó, dữ liệu được dán nhãn được đưa vào một mô hình thống nhất để đào tạo nhằm xác định tất cả các trạng thái an toàn của các bản đồ sao chép cùng một lúc.
2.2 Tăng cường dữ liệu tập dữ liệu dựa trên mạng thần kinh GAN
Sau khi xác định mục tiêu phát hiện, chúng ta cần xây dựng bộ dữ liệu trạng thái an toàn của máy sao chép của riêng mình để tìm hiểu các tính năng cần thiết từ bộ dữ liệu cho các trạng thái khác nhau của máy sao chép bằng các phương pháp học sâu. Tập dữ liệu cần thiết cho việc xây dựng thuật toán trong bài báo này bị chặn từ giám sát video theo dõi mọi thời tiết của một số mô hình. Để giảm ảnh hưởng của môi trường đến các đặc điểm dữ liệu, các điều kiện làm việc như chiếu sáng, che khuất, ngày nhiều mây, mưa và tuyết, ra vào, v.v., được xem xét đầy đủ trong quá trình chuẩn bị tài liệu dữ liệu. Các trạng thái lỗi của máy sao chép trong dữ liệu cũng được thiết lập, tất cả đều đến từ các hình ảnh giám sát bằng video khi lỗi của máy sao chép xảy ra ở dạng chạy chính của tàu có động cơ.
Xem xét rằng một số loại lỗi xảy ra ít thường xuyên hơn trong điều kiện vận hành thực tế, điều này có thể dẫn đến việc chuẩn bị dữ liệu không đầy đủ. Sự mất cân bằng giữa dữ liệu danh mục sẽ ảnh hưởng đáng kể đến hiệu quả nhận dạng mục tiêu, vì vậy bài báo này áp dụng phương pháp tăng cường dữ liệu dựa trên mạng thần kinh GAN cho các danh mục dữ liệu khác nhau.
Generative Adversarial Network GAN chứa hai mô hình, một mô hình tổng quát và một mô hình phân biệt đối xử. Nhiệm vụ của mô hình tổng quát là tạo ra các trường hợp trông thực tế một cách tự nhiên và giống với dữ liệu gốc. Nhiệm vụ của mô hình phân biệt là xác định xem một ví dụ đã cho có vẻ là thật hay giả tạo.
Nó có thể được xem như một trò chơi có tổng bằng không. Trình tạo cố gắng đánh lừa bộ phân biệt đối xử và bộ phân biệt đối xử cố gắng không để bị lừa bởi trình tạo. Các mô hình được đào tạo bằng cách tối ưu hóa thay thế và cả hai mô hình đều có thể được cải thiện. Dựa trên hai mạng này, mạng Generator được sử dụng để tạo ảnh, mạng này nhận nhiễu ngẫu nhiên z và gây ra ảnh bởi nhiễu này, được ký hiệu là G(z). Bộ phân biệt là một mạng phân biệt xác định xem một hình ảnh có"thực tế"hay không. Đầu vào của nó là x, x đại diện cho một bức tranh và đầu ra D(x) biểu thị xác suất mà x là một bức tranh thực tế. Nếu nó là 1, nó có nghĩa là hình ảnh chính xác 100% và nếu đầu ra là 0, nó không thể là hình ảnh chính xác. Sau đó, mạng GAN được hiển thị dưới dạng sơ đồ trong Hình 2. x là dữ liệu thực tế và dữ liệu chính xác tuân theo phân phối Pdata(x). Z là dữ liệu nhiễu và dữ liệu nhiễu phù hợp với phân phối Pz(z), chẳng hạn như phân phối Gaussian hoặc đồng nhất. Sau đó, việc lấy mẫu được thực hiện từ z ồn ào và dữ liệu x=G(z) được tạo sau khi chuyển G. Sau đó, dữ liệu thực tế được đưa vào bộ phân loại D và hàm sigmoid tuân theo thông tin được tạo và đầu ra xác định danh mục.

Hình 2 Sơ đồ nguyên lý mạng GAN
Chuyển đổi hình ảnh thành hình ảnh là một loại bài toán về hình ảnh và đồ họa với mục tiêu là tìm hiểu ánh xạ giữa hình ảnh đầu vào và hình ảnh đầu ra bằng cách sử dụng tập huấn luyện các cặp hình ảnh được căn chỉnh. Mục tiêu của chúng tôi là biết ánh xạ G:X → sao cho phân phối ảnh từ G(X) không thể phân biệt được với phân phối Y bằng cách sử dụng tổn thất đối nghịch. Vì ánh xạ này có giới hạn rất thấp, nên chúng tôi kết hợp nó với ánh xạ ngược F: Y → và đưa ra sự mất tính nhất quán theo chu kỳ để đẩy F(G(X)) ≈ X (và ngược lại). Kết quả định tính được đưa ra trên một số tác vụ không tồn tại dữ liệu đào tạo được ghép nối, bao gồm chuyển đổi phương thức thu thập, biến đổi đối tượng, chuyển đổi theo mùa và nâng cao ảnh. Càng nhiều càng tốt, các cảnh được chọn tương tự hoặc tương tự nhau trong khi chứa các hình ảnh đặc trưng khác nhau. Ví dụ, trong cùng một cảnh, máy ảnh bẩn và không bẩn; máy ảnh có hình ảnh mưa và không mưa. Từ kết quả huấn luyện ta thấy nếu hai ảnh được chọn quá khác nhau về vị trí, các đặc trưng khác đi kèm quá nhiều sẽ ảnh hưởng đến hiệu quả huấn luyện và chất lượng tạo ảnh. Và nếu hình ảnh được tạo ra từ các cảnh tương tự đã chọn có chất lượng chấp nhận được, tác động của việc tăng cường dữ liệu được thể hiện trong Hình 3.

Hình 3 Hiệu ứng nâng cao tập dữ liệu
Ngoài ra, bài báo này còn áp dụng phương pháp lấy mẫu quá mức để mở rộng tập dữ liệu, kết hợp với mạng YOLOV3, đi kèm với các phương tiện tăng cường dữ liệu, cắt xén gói ngẫu nhiên, lật ngẫu nhiên, chuyển đổi sắc độ và các thao tác khác;
Dữ liệu được mở rộng một cách hiệu quả để tăng cường khả năng thích ứng của thuật toán và mang lại độ bền cao hơn để phát hiện các đối tượng trong giai đoạn triển khai sử dụng thực tế. Tuy nhiên, để phân biệt giữa các góc cung trái và phải, các công tắc lật và xoay ngẫu nhiên bị tắt trong thuật toán của bài báo này.
2.3 Tối ưu thuật toán nhận dạng trên mạng YOLOV3
Phần xương sống của YOLOV3 sử dụng cấu trúc Darknet53 của tác giả, cấu trúc này có thể giải quyết các vấn đề về biến mất độ dốc và bùng nổ độ dốc bằng cách kết hợp mạng thần kinh tích chập (CNN) và mạng cấu trúc dư (ResNet), giúp việc đào tạo mạng sâu trở nên khả thi. Ngoài ra, thuật toán không cần tính toán trước các hộp ứng cử viên. Tuy nhiên, nó có được BondingBox tiên nghiệm bằng cách phân cụm, chọn 9 cụm và ba tỷ lệ, đồng thời phân bổ đều 9 cụm này trên ba tỷ lệ này. Tuy nhiên, do vấn đề về tỷ lệ, độ chính xác của thuật toán YOLO không phải là tốt nhất trong số các thuật toán nhận dạng mục tiêu, đặc biệt là trong việc phát hiện các mục tiêu nhỏ. Để cải thiện độ chính xác phát hiện của thuật toán YOLOV3 trong khi vẫn duy trì tốc độ cao, xương sống của YOLOV3 đã được sửa đổi. Phương pháp cụ thể là thêm mô-đun SE chú ý kênh vào đơn vị còn lại của darknet53. Cấu trúc của đơn vị mạng còn lại trước và sau khi chuyển đổi được hiển thị trong Hình 4.

Hình 4 Cấu trúc còn lại của module SE trước và sau khi sửa đổi
Mô-đun SE đến từ SENet, viết tắt của Squeeze-and-Excite Networks, đã giành chức vô địch cuộc thi phân loại ImageNet 2017, được công nhận về tính hiệu quả và dễ triển khai, đồng thời có thể dễ dàng tải vào các khung mô hình mạng hiện có.SENet chủ yếu học các tương quan giữa các kênh và lọc bớt sự chú ý cho các kênh, điều này làm tăng tính toán một chút, nhưng hiệu quả tốt hơn. Phần xương sống của Darknet có tổng cộng 23 đơn vị mô-đun còn lại. Trong bài báo này, các đơn vị Res ban đầu được chuyển đổi thành các đơn vị SE-Res cho một số đơn vị còn lại. Để cải thiện khả năng phát hiện của mạng YOLOV3 đối với các mục tiêu vừa và nhỏ, các đơn vị còn lại chúng tôi đã thay đổi cũng nằm trong hai nhánh này. Kiến trúc mạng tổng thể của YOLOV3 được chuyển đổi bởi mô-đun SE được hiển thị trong Hình 5.

Hình 5 Sơ đồ cấu trúc mạng YOLOV3
Trong phần mạng nhận dạng, YOLOV3 được tạo ra mạnh mẽ hơn bằng cách lấy mẫu lên và xếp tầng chéo lớp để tạo ra ba thang kết quả phát hiện khác nhau. Trong phần thiết kế hàm mất mát, độ tin cậy, danh mục và vị trí mục tiêu được học cùng một lúc bởi hàm mất mát entropy chéo và hàm mất mát được hiển thị trong Phương trình 1.

3. Phân tích kết quả thí nghiệm
3.1 Giới thiệu máy chủ phân tích thông minh của Tienuo
Hầu hết các hệ thống giám sát video trong xe hiện có chỉ có chức năng giám sát và lưu trữ video nhưng không có khả năng phân tích trực tuyến thông minh. Phần cứng của bài báo này được triển khai với sự trợ giúp của máy chủ phân tích thông minh tích hợp do Shandong Tienuo Intelligent Co. phát triển, như thể hiện trong Hình 6. Máy chủ được trang bị chip thông minh AI kiến trúc Da Vinci do Huawei tự phát triển ATLAS 3000, có thể đối phó với các ứng dụng phân tích sáng tạo trong hầu hết các tình huống và thực hiện các nhiệm vụ giải mã và phân tích thông minh lên đến 16 kênh video 720p. Và kết quả kiểm tra có thể được truyền đến buồng lái của người lái xe hoặc thợ máy trong thời gian thực để có thể xem xét kết quả kiểm tra theo cách thủ công và có thể thực hiện các biện pháp an toàn tương ứng. Bài báo này sử dụng phần cứng này để đạt được tốc độ tính toán 60 khung hình/giây khi chạy một kênh video camera đơn. Việc phân tích đồng thời 4 kênh của nhiều video cũng có thể đảm bảo tốc độ tính toán là 25 khung hình/giây, có thể đáp ứng nhu cầu phân tích thông minh theo thời gian thực của video đa kênh.

Hình 6 Sơ đồ giao diện và máy chủ phân tích thông minh
3.2 Kết quả nhận dạng trạng thái Pantograph
Để phát hiện trạng thái an toàn của máy sao chép, bài viết này xây dựng bộ dữ liệu trạng thái an toàn của máy sao chép, chứa 2388 ảnh thuộc nhiều dạng khác nhau của máy sao chép, bao gồm cả hình ảnh theo dõi ở trạng thái bình thường và hình ảnh giám sát của máy sao chép ở trạng thái bất thường trong các điều kiện làm việc khác nhau. Tập dữ liệu có nhãn được đào tạo bằng cách sử dụng khung darknet và quy trình đào tạo được hiển thị trong Hình 7. Từ hình này có thể thấy rằng tổn thất đào tạo vẫn ổn định sau 12000 lần lặp và mô hình có thể rơi vào trạng thái tối ưu cục bộ. Tỷ lệ học tập được điều chỉnh một lần ở 20000 lần lặp lại và tổn thất giảm xuống dưới 0,1. Sự cải thiện về độ chính xác tính toán từ 20.000 lần lặp trở đi là không đáng kể và biểu đồ mAP tương ứng cho thấy khả năng khái quát hóa của mô hình bị giảm nhẹ. Để xem xét tổn thất đào tạo và mAP,

Hình 4 Quy trình đào tạo nhận dạng trạng thái an toàn của Pantograph
Để triển khai mô hình được đào tạo cho máy chủ phân tích thông minh, mô hình được đào tạo cần được chuyển đổi sang định dạng om được hỗ trợ bởi kiến trúc Huawei da Vinci, với một chút mất đi độ chính xác trong quá trình chuyển đổi, nhưng tất cả đều nằm trong phạm vi chấp nhận được.

4. Tóm tắt và triển vọng
Bài báo này sử dụng thuật toán YOLOV3 để phát hiện trạng thái an toàn của các máy sao chép, bao gồm các bất thường về cấu trúc, tia lửa và sự xâm nhập của vật thể lạ, thông qua giám sát video thời gian thực, có tính đến tốc độ phát hiện đồng thời đảm bảo độ chính xác của phát hiện đáp ứng các yêu cầu của thực tế. phân tích thời gian. Nó cung cấp những ý tưởng mới để sử dụng hệ thống phân tích thông minh tích hợp trong quá trình kiểm tra an toàn của máy sao chép.